多模态智能实验室¶

研究领域¶
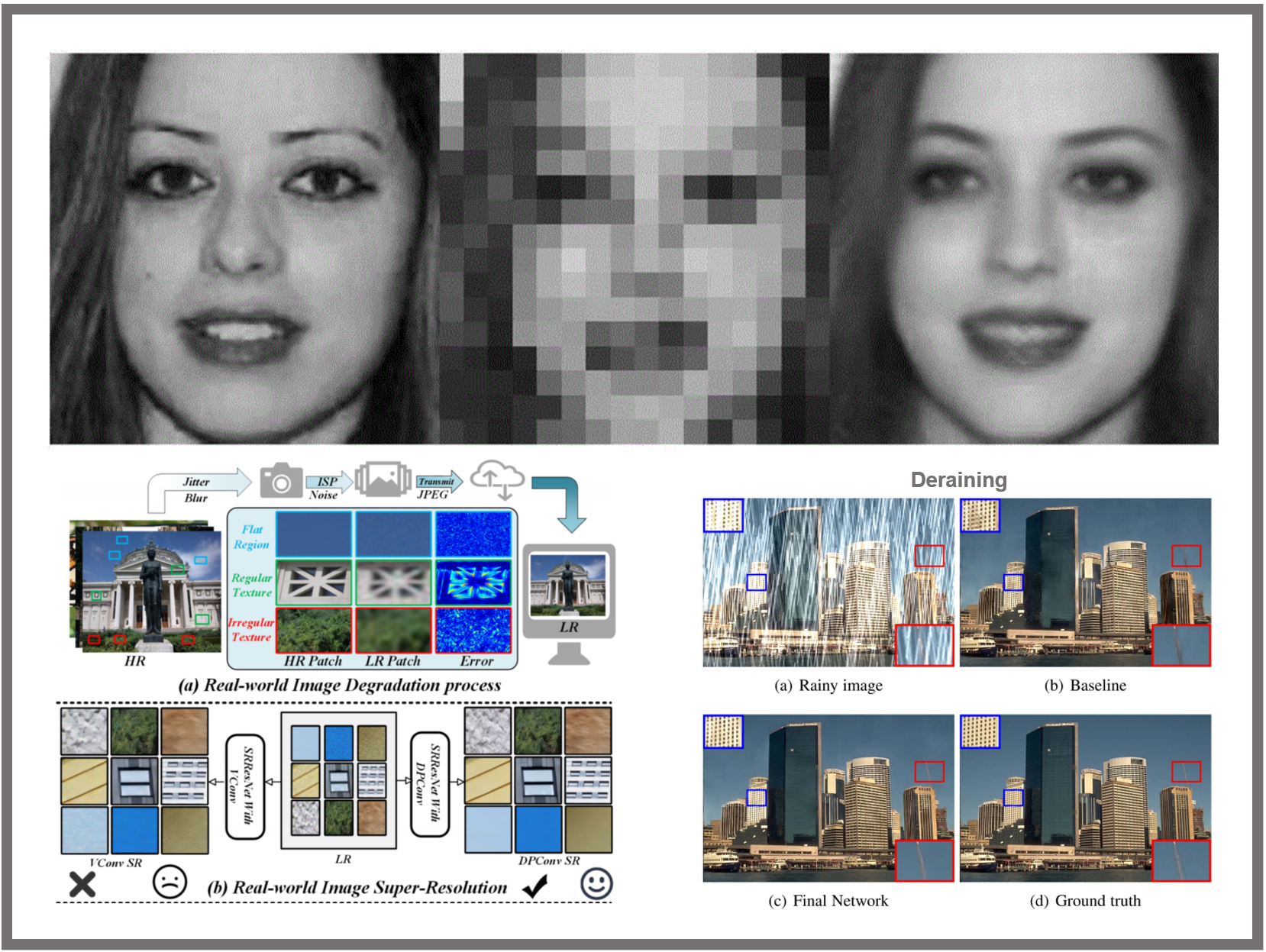
视觉增强与复原¶
视觉增强与复原领域致力于提升和恢复图像和视频的质量,其目标是将受损、模糊或低分辨率的视觉数据转化为清晰、高质量的图像和视频。通过应用先进的图像处理算法和深度学习技术,研究人员能够在去噪、超分辨率、去模糊、色彩校正和图像修复等方面取得显著进展。例如,图像去噪技术可以有效减少噪点,提高图像的清晰度和细节表现;超分辨率技术能够从低分辨率图像生成高分辨率图像,恢复更多细节;去模糊技术则可以消除由于相机抖动或运动造成的模糊效应。此外,色彩校正和增强技术可以优化图像的色彩表现,使其更加真实和生动;图像修复技术可以填补图像中的缺失部分,如修复破损的老照片。这些技术在医疗成像、卫星图像处理、视频监控和数码摄影等领域具有广泛的应用前景。
视觉识别与分析¶
视觉识别与分析研究方向聚焦于从图像和视频中提取有意义的信息和模式,其核心任务是通过计算机视觉技术实现对视觉数据的理解和解释。具体来说,目标检测技术用于识别图像中不同的物体并标注它们的位置;图像分类技术根据图像内容将其分类到特定的类别中;人脸识别技术可以识别和验证人脸身份;行为识别技术分析和识别视频中人类的行为和动作;而场景理解技术则从整体上理解图像中的场景,包括物体之间的关系和背景信息。这些技术在安防监控、自动驾驶、智能家居、医疗诊断和人机交互等领域具有重要的应用价值,能够为社会带来更智能和便捷的解决方案。
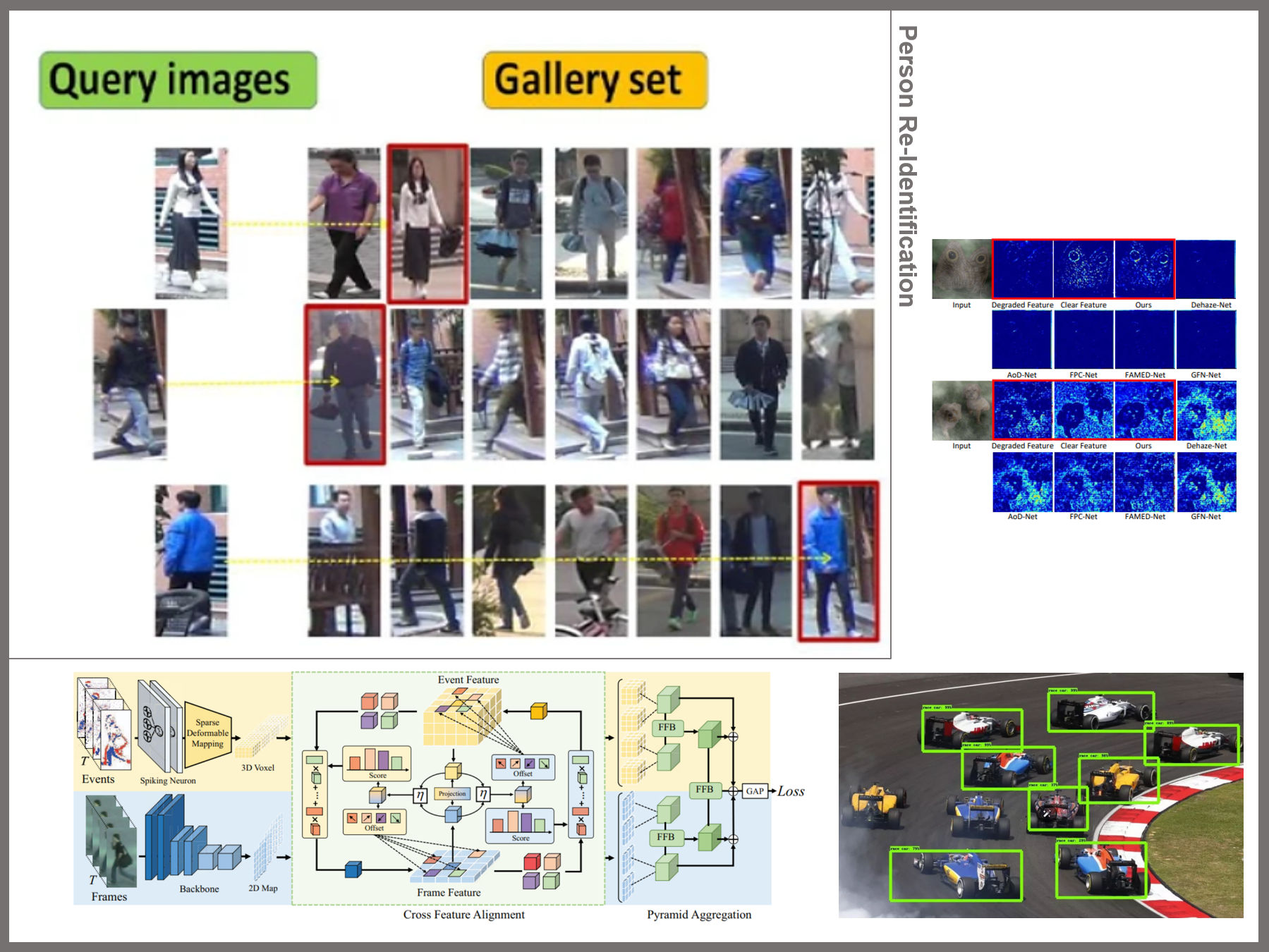
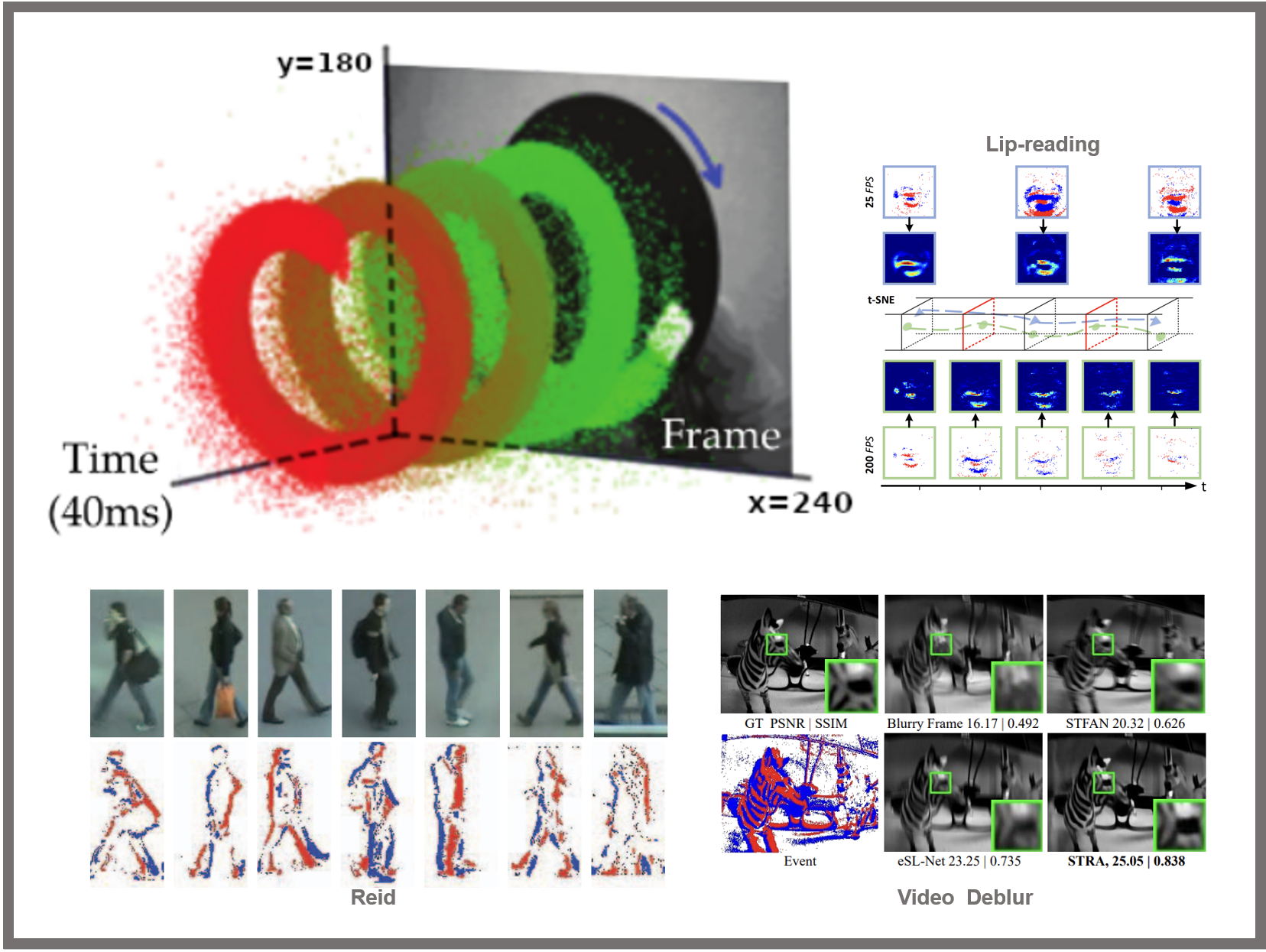
神经形态视觉¶
神经形态视觉研究基于生物神经系统的工作原理,旨在设计和实现具有类脑功能的视觉系统。该领域借鉴了神经科学和电子工程的知识,致力于开发高效的视觉处理硬件和算法。例如,事件驱动的视觉传感器模仿人类视网膜的工作方式,能够高效地处理动态场景;脉冲神经网络利用脉冲信号进行信息处理,提高了计算效率和速度;低功耗视觉处理系统设计则适用于资源受限的环境,如移动设备和嵌入式系统;神经形态计算架构通过仿生设计提升视觉处理的速度和效率。这些技术有望在机器人视觉、自动驾驶、智能监控和可穿戴设备等领域实现突破,提供更自然、更高效的视觉感知能力。
多模态理解与生成¶
多模态理解与生成方向探索如何综合和处理来自不同模态的信息(如视觉、听觉、语言等),以实现更智能和全面的系统。研究人员开发了跨模态检索技术,从一个模态(如文本)中检索另一个模态(如图像)中的相关内容;图像字幕生成技术根据图像内容生成自然语言描述;视觉问答技术可以根据图像内容回答用户提出的问题;语音和图像的联合生成技术则可以生成与语音描述相匹配的图像,或根据图像内容生成语音描述。此外,多模态融合模型能够同时处理和理解多种模态信息,提供更全面的分析和生成能力。这些技术在人机交互、智能助理、内容生成和虚拟现实等领域具有广泛的应用潜力,能够实现更加自然和智能的多模态交互。
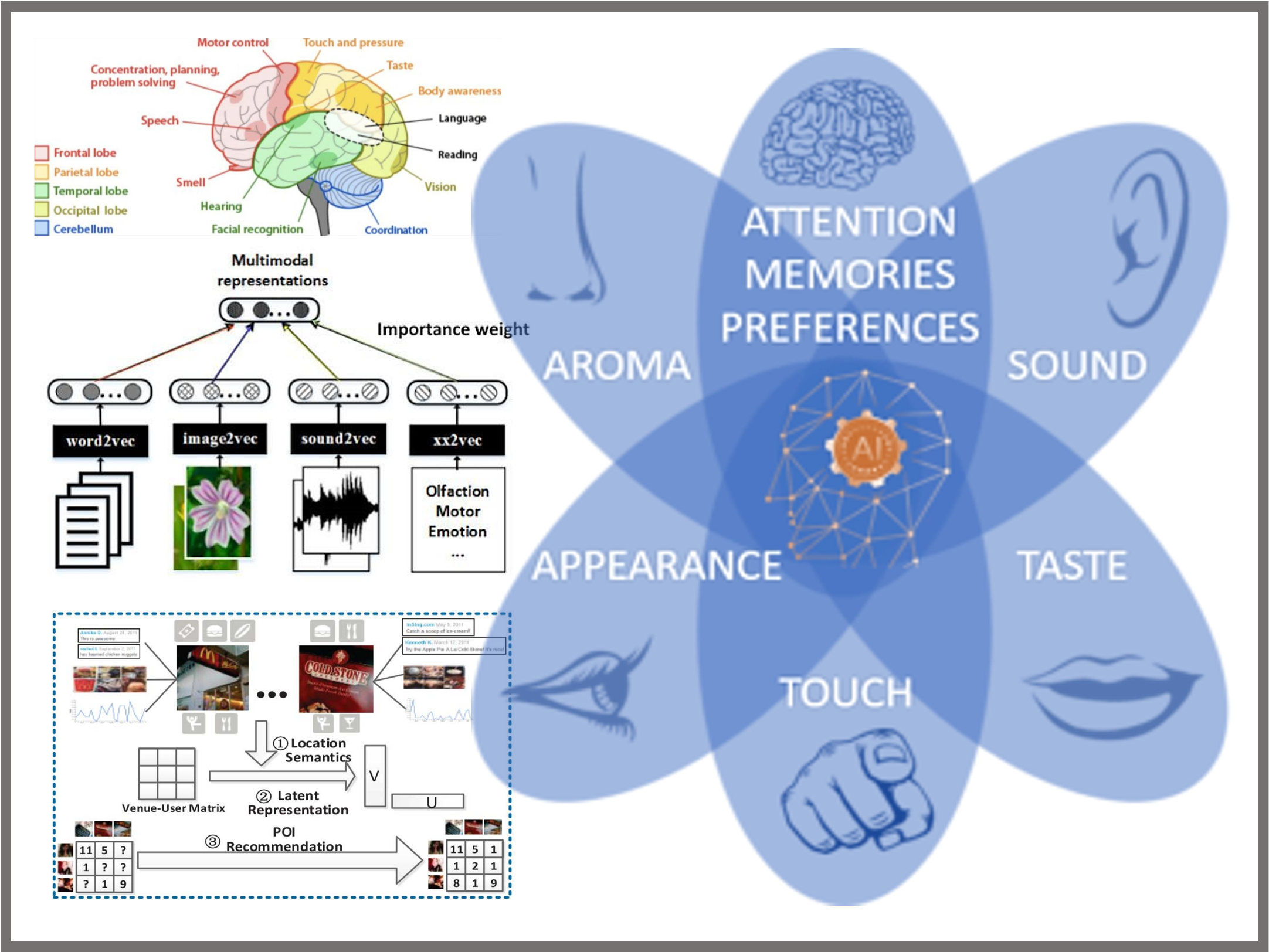
具身智能¶
具身智能研究方向旨在赋予机器人和智能体以感知、理解和行动的能力,使其能够在现实世界中完成复杂任务。通过研究机器人感知、运动规划和控制、人机交互、自主导航和任务学习与执行,机器人能够更好地与环境和人类互动,执行复杂的物理和认知任务。具体来说,机器人感知技术使其能够理解和适应环境;运动规划和控制技术使机器人能够灵活地移动和操作物体;人机交互技术研究机器人如何与人类进行自然和有效的沟通与合作;自主导航技术使机器人能够在未知环境中安全移动;任务学习和执行技术则研究智能体如何学习和执行复杂任务,如抓取、组装和探索。这些技术在服务机器人、工业自动化、医疗机器人和智能家居等领域具有重要的应用价值,推动了机器人技术的发展和普及。
校企合作¶











